Introduction to Graph query language Cypher
This introduction to cypher graph query language is based on a database of movies.
Open the toggle triangles for instructions details.
Create db & connect with workspace
- go to Neo4j sandbox https://sandbox.neo4j.com/
- create yourself an account
- log in
- create a movie data base instance
- and open it the workspace
Your firsts cypher queries
1. Some data is preloaded in the db. Let’s look at what it is.
- Clicking on the database icon opens a pannel that lists all different node labels, relation types and properties (for nodes or relations).
The number of nodes (170) and relationships (252) is also indicated.

- To return the whole data base, run this query
match path=()--() return path
!!! Not to be run on a database of more than a couple hundreds items !
- Explore the data in the browser
-
expected result
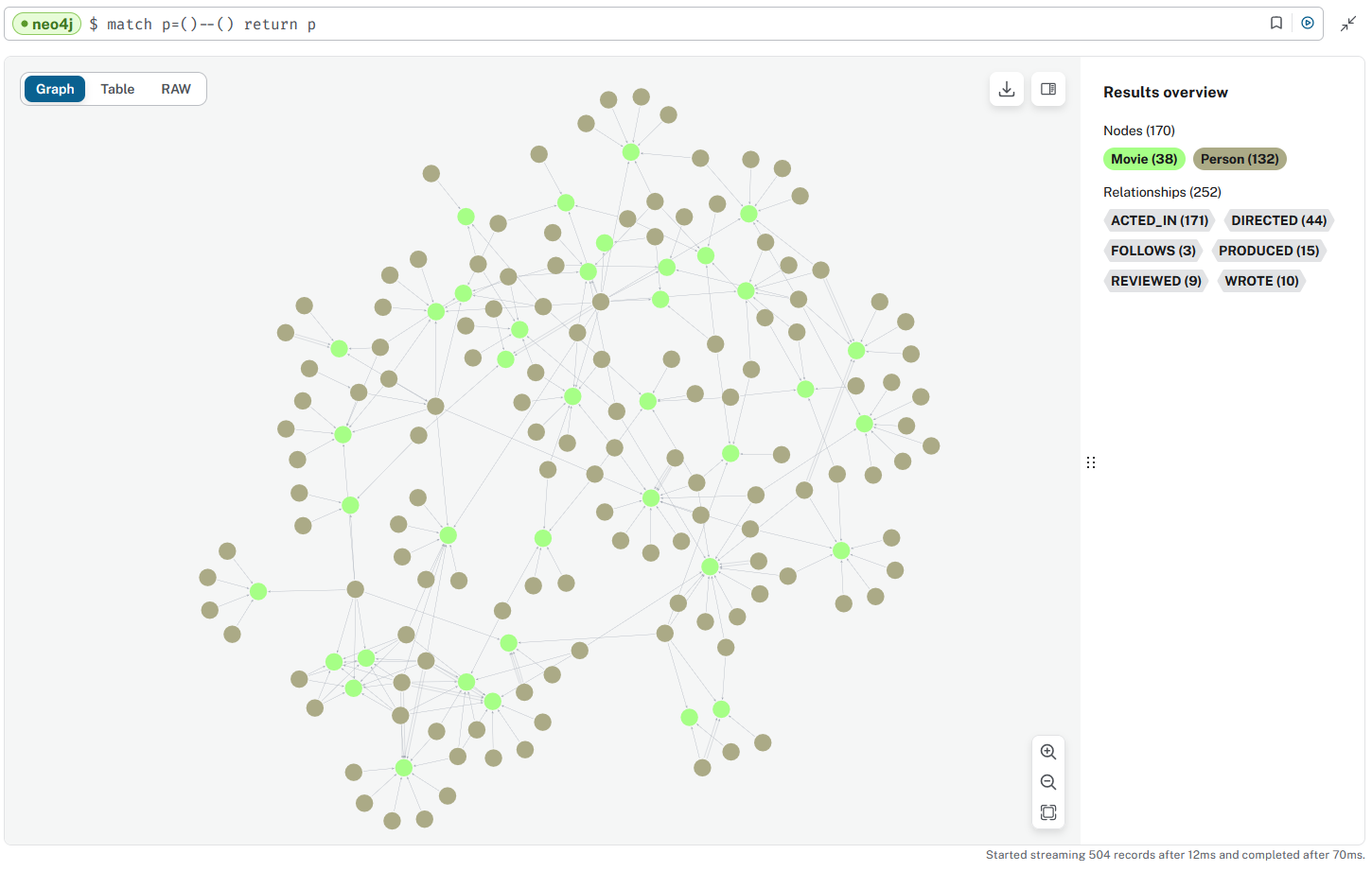
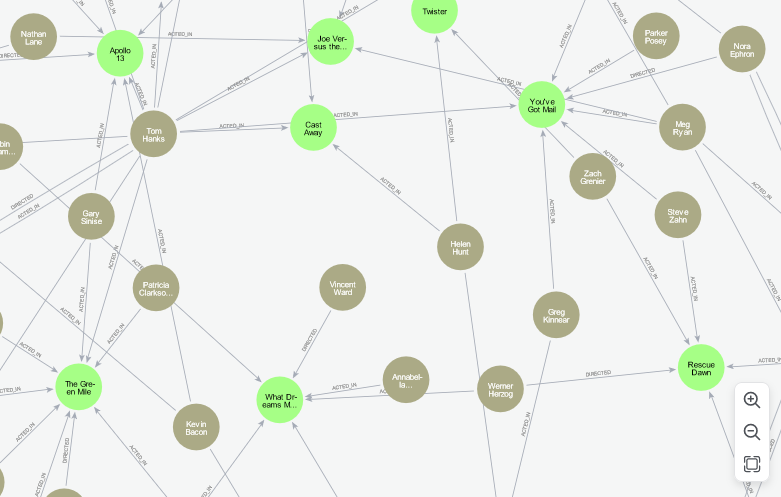
-


- in the left panel, click on one label
- in the left panel, click on the property ACTED_IN
- run CALL db.schema.visualization()
The schema of the database is an agregated view by labels and relations types : it represents all existing labels and the relation types that exists between them
-
expected result
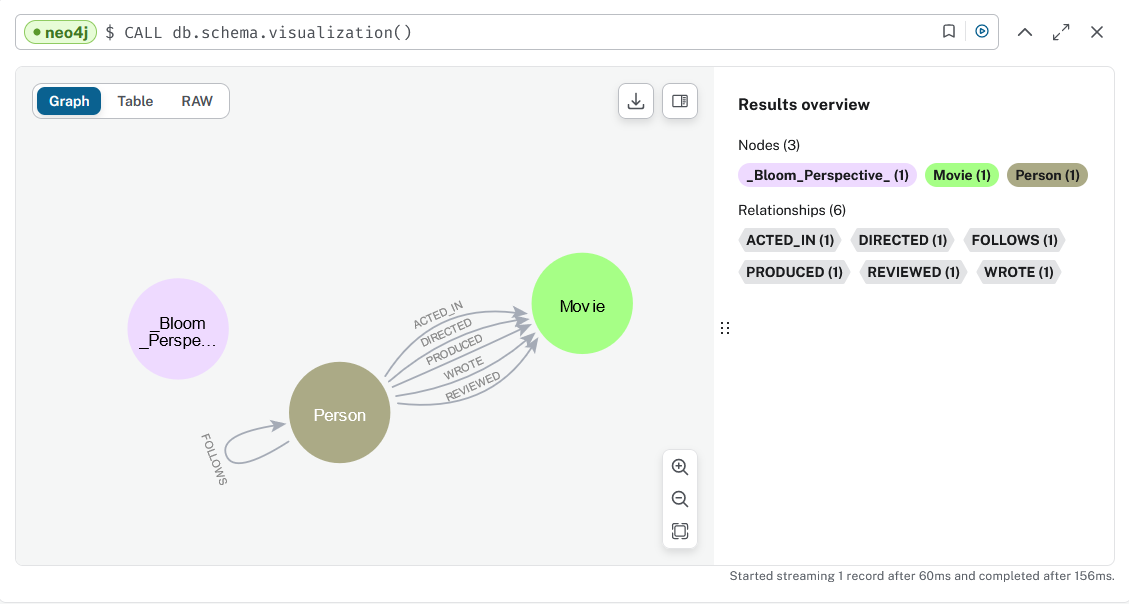
-

2. Graph pattern - display properties
What is the movie Keanu Reeves acted in ?

Run the query :
MATCH (m:Movie)-[:ACTED_IN]-(p:Person WHERE p.name = "Keanu Reeves")
RETURN m.title
m and p are variables . They can be used to specify the pattern after the WHERE keyword, or to specify what will be returned by the query.
-
expected result
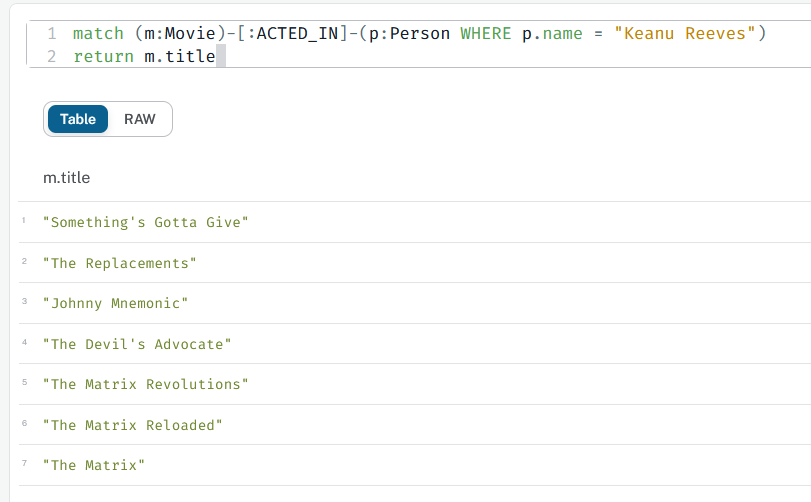

for later reference more about MATCH in the documentation
for later reference more about allowed expressions in Cypher
3. Syntactic equivalence
The following 3 syntax run the exact same query
match (m:Movie)-[:ACTED_IN]-(p:Person {name : "Keanu Reeves"})
return m.title
match (m:Movie)-[:ACTED_IN]-(p:Person WHERE p.name = "Keanu Reeves")
return m.title
match (m:Movie)-[:ACTED_IN]-(p:Person)
WHERE p.name = "Keanu Reeves"
return m.title
the WHERE keyword allows to specify all sorts of constrains on the pattern
for later reference more about WHERE in the documentation
4. Graph pattern - display nodes and relations in a graph form
Run the query :
match (m:Movie)-[r:ACTED_IN]-(p:Person WHERE p.name = "Keanu Reeves")
return m,r,p
-
expected result
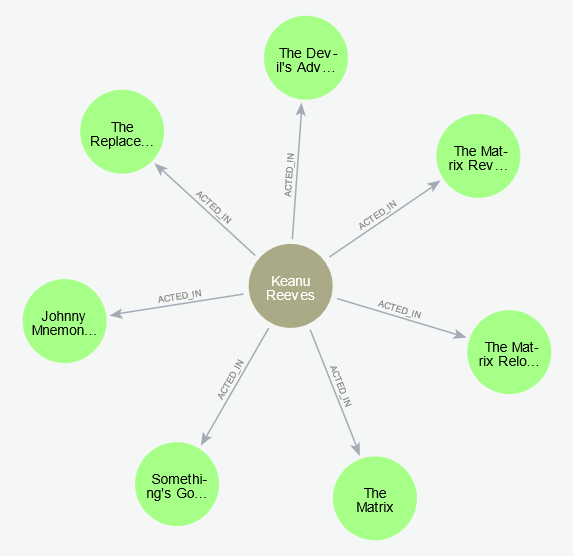

How do you explain the results of query 2 ?
-
explanation
The query returns all movie titles that match the pattern. That is all movie titles the node representing Keanu Reeves is related to with an ACTED_IN relationship, like we can see in the output of query 4.
Graph patterns practice
1. Run a query that returns "Tom Hanks" and all related nodes, by any kind of relationship
-
expected result
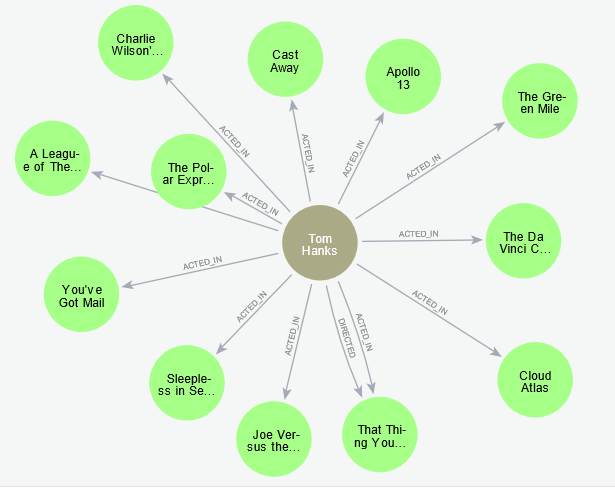

-
query
match (m:Movie)-[r]-(p:Person {name : "Tom Hanks"})
return m,r,por
match (m:Movie)-[r]-(p:Person) WHERE p.name = "Tom Hanks"
return m,r,por
match (m:Movie)-[r]-(p:Person WHERE p.name = "Tom Hanks")
return m,r,p
-
explanation
As the type of the relationship is not sepcified in the query (contrary to what we had in query 2. and 4.) all kinds of relationships are returned
2. What are the title(s) of the movie(s) released in 1999 ?
-
expected result


-
query
match (m:Movie WHERE m.released = 1999)
return m.title
-
explanation
The query can specify any properties, on nodes or relationships
3. Who played with Keanu Reeves in “The Matrix” ?
-
hint
What we are looking for is the name property of nodes p:Person, that are related to the node representing "The Matrix", by an :ACTED_IN relationship.
As we want people who played with Keanu Reeves, and not himself, do not forget to accordingly add a constrain on p:Person.
-
expected result
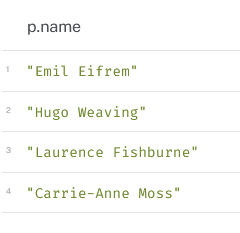

-
query
match (m:Movie WHERE m.title="The Matrix")-[:ACTED_IN]-(p:Person where p.name <> "Keanu Reeves")
return p.name
4. Emil Eifrem founded Neo4j in 2007. Match and return the node for Emil with a variable e and figure in what year he was born.
-
tip
to match with a string, instead of equal, you can use STARTS WITH, ENDS WITH and CONTAINS
-
expected result
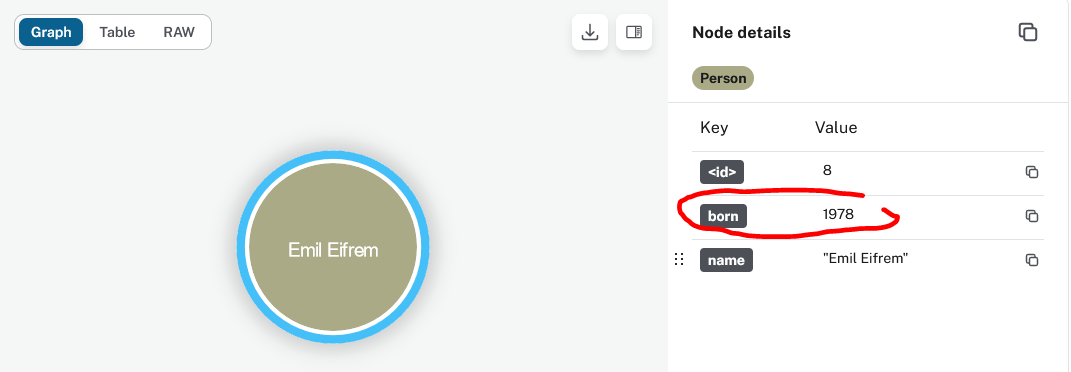

-
query
match (e:Person) where e.name STARTS WITH "Emil"
return ewrong output :
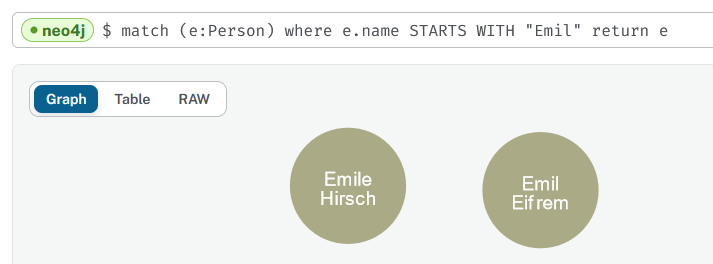
match (e:Person) where e.name CONTAINS "Eifrem"
return eor
match (e:Person) where e.name = "Emil Eifrem"
return e

-
take away
STARTS WITH, ENDS WITH and CONTAINS are useful to display node without having to write the exact value of a property (that can be long). When deleting nodes though, it is safer to use very specific constrains (like = ) to make sure the pattern only matches the intended node.
The specificity of the matched pattern depends on what is in the db, therefore what a query returns can change if data is added.
5. Delete a node
Actually, Emil did not play in “The Matrix”.
In the appropriate previous command (the one that matches only Emil), replace return by detach delete e to remove Emil’s node.
-
expected result

Make sure the indicated number of delete nodes and relationships corresponds to the number you intended to delete.

-
query
match (e:Person where e.name ="Emil Eifrem")
detach delete e
for later reference more on DELETE in the documentation
6. Replay query 3. and check that Emil is not in the list anymore

7. What are the names of the caracters in “The Matrix” ?
-
hint
With the same query, you can return who played the caracter. Use a property on a relationship.
-
expected result


-
query
match (m:Movie WHERE m.title="The Matrix")-[r:ACTED_IN]-(p:Person)
return r.roles
8. Who both directed and acted in the same movie ?
-
hint
The pattern you are looking for is
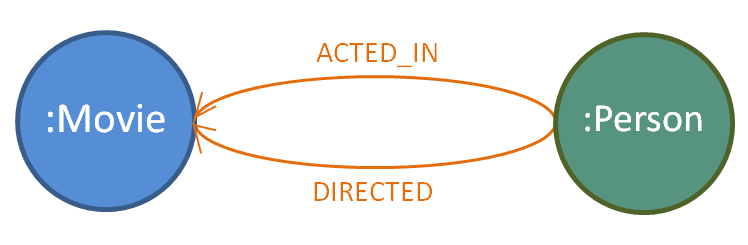
Remember of variables : the same variable name always refer to the same element.

-
expected result


-
query
match (p:Person)-[:ACTED_IN]-(m:Movie)-[:DIRECTED]-(p)
return p.name,m.title
9. Aggregate nodes information with COLLECT()
- return all actors names with the title of the movies they acted in. Add order by p.name at the end of the return
so the results will be sorted by the actor’s name
-
expected result

-
query
MATCH (p:Person)-[:ACTED_IN]->(m:Movie)
RETURN p.name,m.title order by p.name
for later reference more about ORDER BY in the documentation
In this output, we see that one line is produced for each movie an actor acted in (see Ben Miles).
-

- Instead of m.title (to display the movie title), use collect(m.title)
and see what happens
-
expected result

-
query
MATCH (p:Person)-[:ACTED_IN]->(m:Movie)
RETURN p.name,COLLECT(m.title) order by p.name
-
take away
To get a line per actor, with the titles of the movies he acted in as a list, we have used collect(m.title).
-

for later reference more about COLLECT() in the documentation
10. alias, COUNT() and labels(n)
- Rerun the previous query with count() instead of collect() :
MATCH (p:Person)-[:ACTED_IN]->(m:Movie)
RETURN p.name as name ,count(m.title) as count order by nameas allows you to alias an output field to a name. This name will appear as header of the output colomn and it is to be used later in the query, for example with the ORDER BY keyword
-
expected result
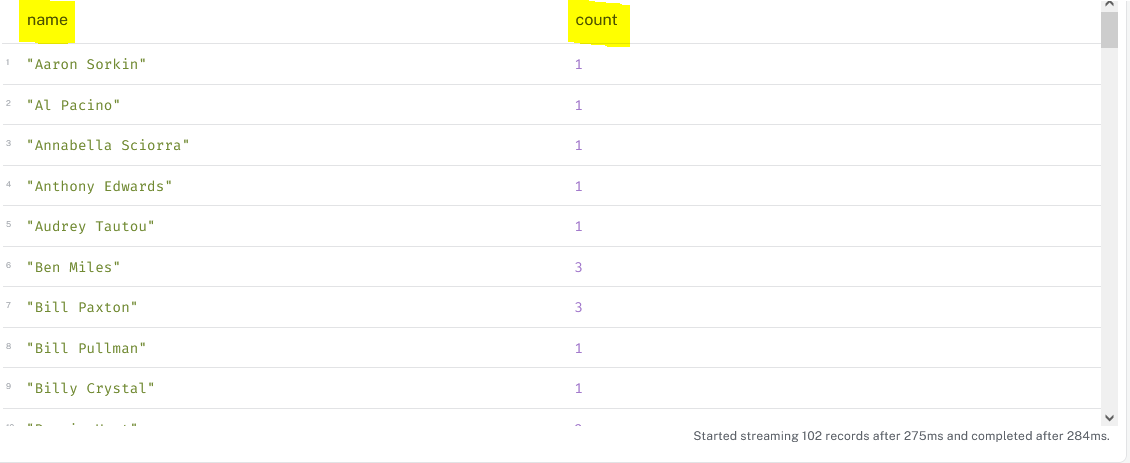
labels(n) return the list of labels of a node
-

- write and run a query that returns the list of labels with the number of corresponding nodes
-
expected result

-
query
match (n) return labels(n), count(n)
-

for later reference more about COUNT() in the documentation
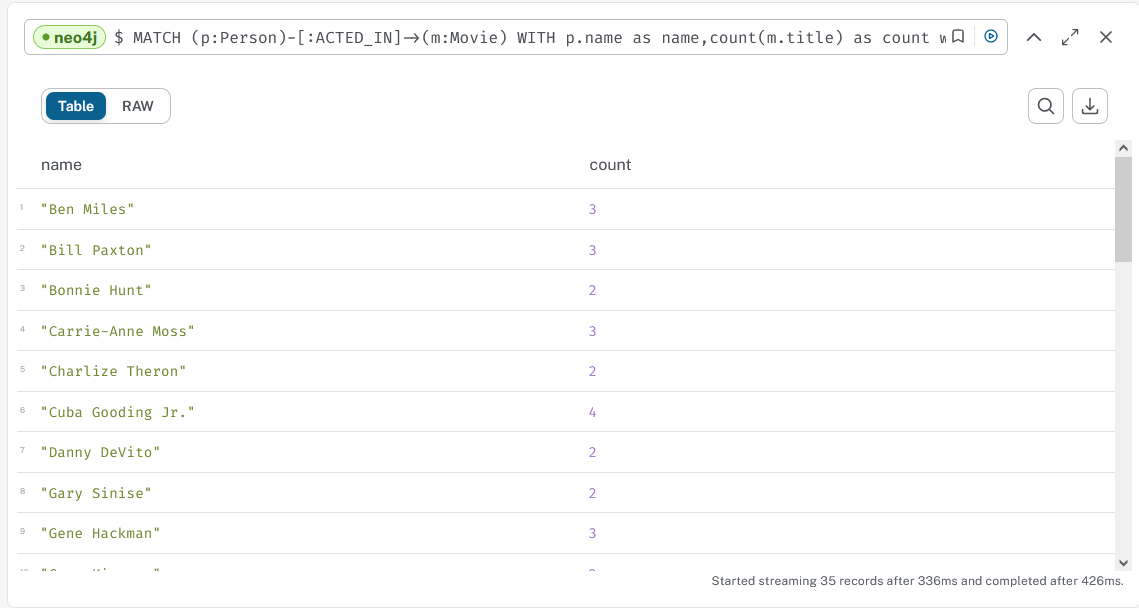
11. WITH
The WITH keyword allows to select part of the matched results to be used as starting point for further filtering
- run
MATCH (p:Person)-[:ACTED_IN]->(m:Movie)
WITH p.name as name, COUNT(m.title) as count WHERE count > 1
RETURN name,count order by nameWhat do you expect the result of this query to be ?
-
expected result
-
explanation
After selecting the pattern described after MATCH, the WITH keywords selects some elements and COUNT(m.title) is aliased to count The added WHERE clause filters further on rows with count >1. As a result, the query returns the name of actors who played in more than one movie, together with the number of movies they played in.
-

- Write and run a query that returns the names of the actors that played in at least 5 movies, together with the titles of the movies they played in
-
expected result

-
query
MATCH (p:Person)-[:ACTED_IN]->(m:Movie)
WITH p.name as name,count(m.title) as count , collect (m.title) as movies where count > 5
RETURN name,movies order by name
-

for later reference more on WITH in the documentation
Graph patterns practice Take away
Graph pattern matching is like writing a filter “shape” : you specify a configuration of nodes, properties values or existence (on nodes or relations), node labels can also be in a pattern and relations between node can also be part of that “shape”. The query engine will sort of pass this filter “shape” through the graph, to grab corresponding portions of the graph.
In the return clause, you pick in the matched pattern, whatever it is you want to display.
Import data
csv file
look at this csv file (thanks Priya Jacob for sharing it online!)
https://raw.githubusercontent.com/priya-jacob/pinkprogramming/main/movies.csv
It contains a list of movie titles, together with a list of genre the movie is categorised in, the list of its directors and actors, etc.
load more data
run this query
LOAD CSV WITH HEADERS FROM 'https://raw.githubusercontent.com/priya-jacob/pinkprogramming/main/movies.csv' AS row
WITH row
MERGE (n:Movie {title: row.title})
SET
n.year = row.year,
n.summary = row.summary,
n.runtime = toInteger(row.runtime),
n.certificate = row.certificate,
n.rating = toFloat(row.rating),
n.votes = toInteger(row.votes),
n.gross = toFloat(row.gross),
n.Pink=true
FOREACH (x IN split(row.genre, ',') | MERGE (g:Genre {genre: trim(x)}) ON CREATE SET g.Pink=true MERGE (n)-[:GENRE]->(g))
FOREACH (x IN split(row.actors, ',') | MERGE (p:Person {name: trim(x)}) ON CREATE SET p.Pink=true MERGE (p)-[:ACTED_IN]->(n))
FOREACH (x IN split(row.directors, ',') | MERGE (p:Person {name: trim(x)}) ON CREATE SET p.Pink=true MERGE (p)-[:DIRECTED]->(n))
-
expected result


This query uses MERGE to create nodes when they do not alredy exists. It is spliting fields genre, directors and actors with the coma as separator, to relate :Movie nodes to all corresponding genres, directors and actors, using the FOREACH keyword. The query also sets node property values (year, summary,etc.)
for later reference more on LOAD CSV in the documentation
for later reference more on MERGE in the documentation and a 10' video explaining cypher MERGE
for later reference more on FOREACH in the documentation
Explore nodes with the new :Genre label
- rerun the query giving the number of nodes per label
-
expected result

-

- click on the new genre label
- double click on one node labeled :Genre
Indexes & Constraints
- run the query SHOW INDEX

To speed up query processing, indexes are very important to have on properties that are often used in query patterns
- lets create a constraint for nodes labeled with :Genre, to make sure we do not create several :Genre nodes with the same genre property
run CREATE CONSTRAINT c_movie_genre IF NOT EXISTS FOR (g:Genre) REQUIRE g.genre IS UNIQUE;

- run SHOW INDEXES again

When you create a uniqueness constrain, you get an index for free !
for later reference more on CONSTRAINTS in the documentation
for later reference more on INDEXES in the documentation
how do you expect the new db schema to look like ?
run CALL db.schema.visualization() to check
-
expected result
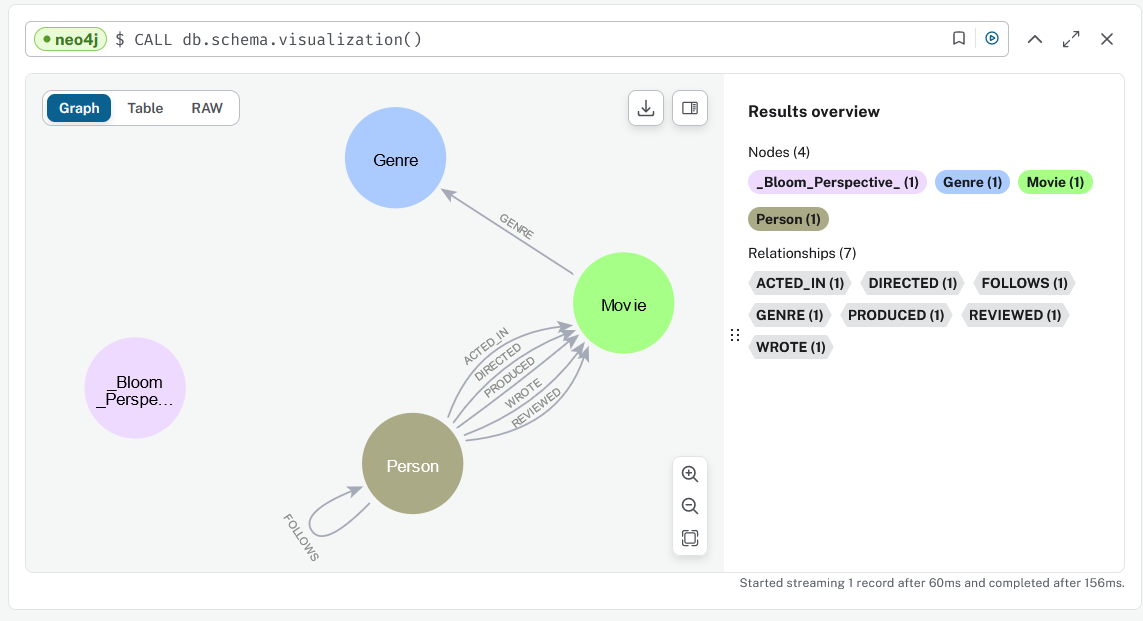

Data categorisation with Label Property Graph databases
movies by genre
Write and run a query that returns the list of genre in alphabetical order, with for each, the list of corresponding movies
-
expected result
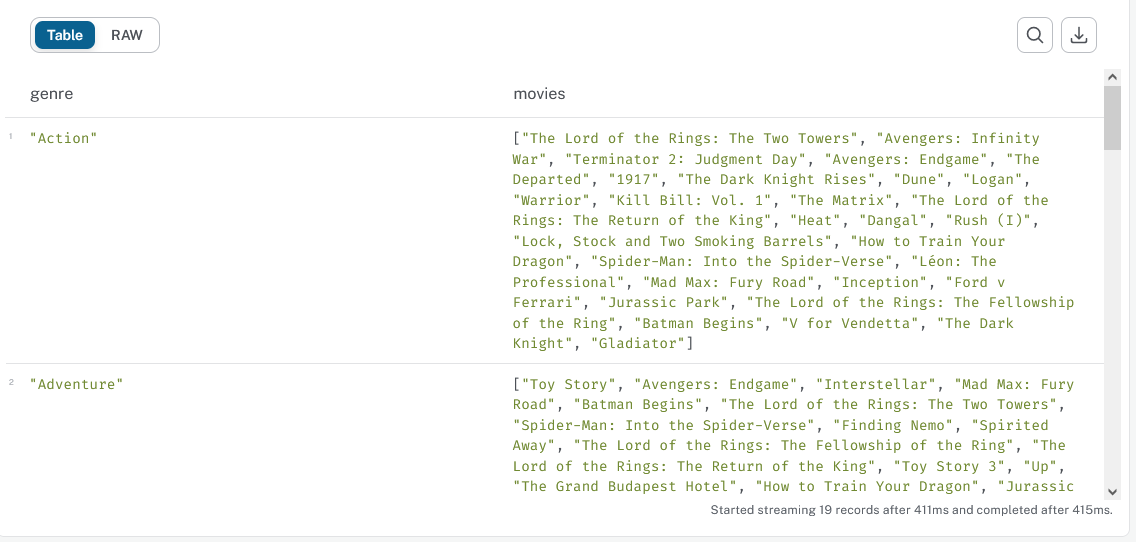

-
query
match (g:Genre)<--(m:Movie)
return g.genre as genre,collect(m.title) as movies order by genre
newly imported data
When we imported new data, we’ve added a property n.Pink = True to new and updated nodes
- Write and run the query that returns the number of newly imported and updated nodes
-
expected result


-
query
match (n) where n.Pink return labels(n),count(n)
- run the query match (n) where n.Pink set n:New
What do you think this query does ?
-
answer
It adds a label :New to evry selected nodes, in this case, the node with the property n.Pink=True
- now, what are the 2 ways to list the names of newly imported actor names ?
-
queries and result
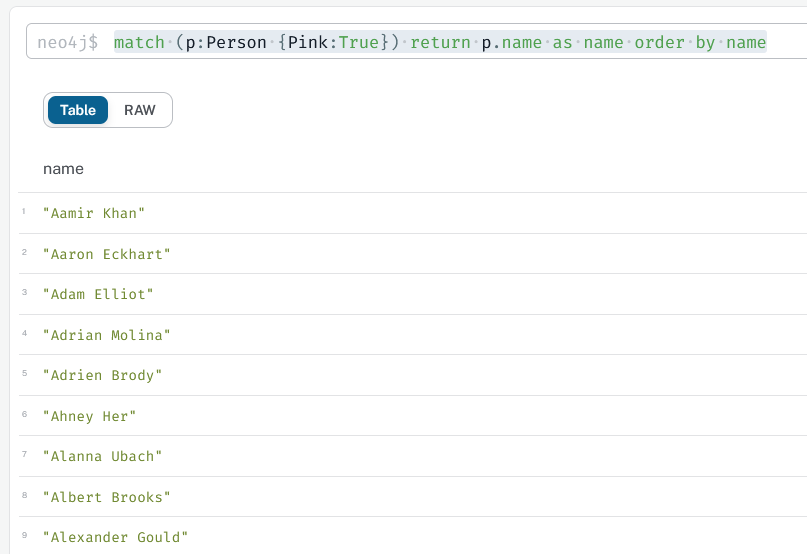
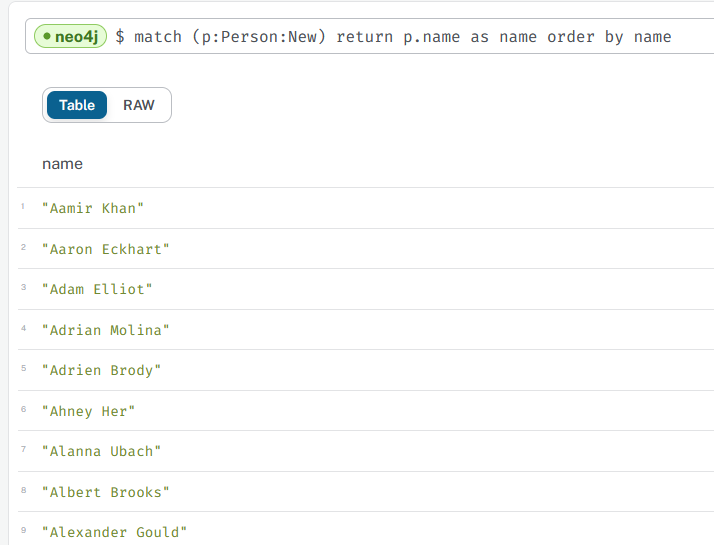


Categorisation with Label Property Graph databases Take away
With Label Property Graph (LPG) databases, there are 3 ways to categories nodes. With :
- a property
- a class node (:Genre)
- a label
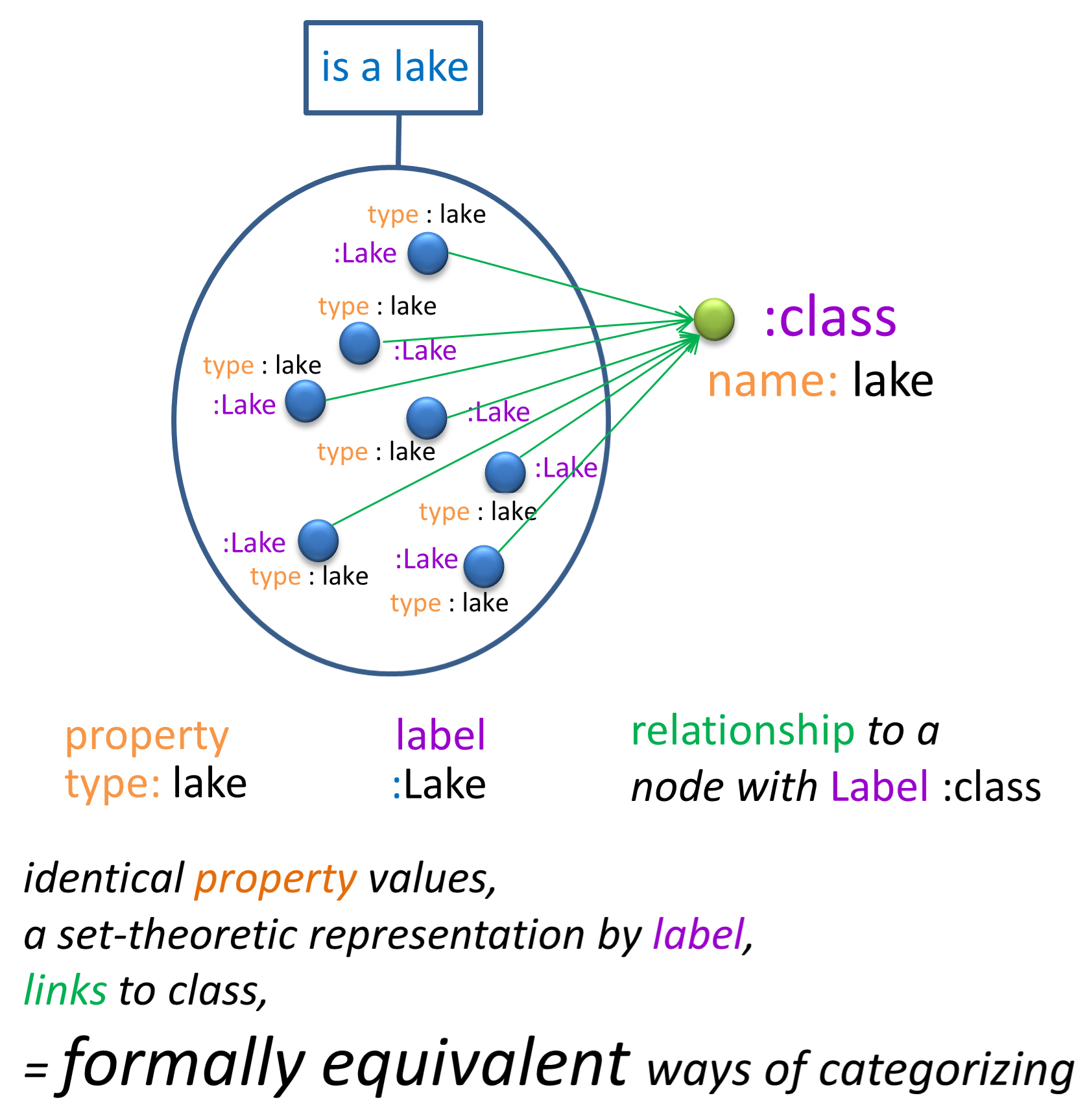

Relations transitivity
Relation transtivity is when (A)-[rel]→(B) and (B)-[rel]→(C) then (A)-[rel]→(C)
In the database, only movies are attached to node :Genre. Using relation transitivity how can you produce the list of actors with for each, the list of genre of the movies they played in ?
You will need the DISTINCT operator
-
expected result
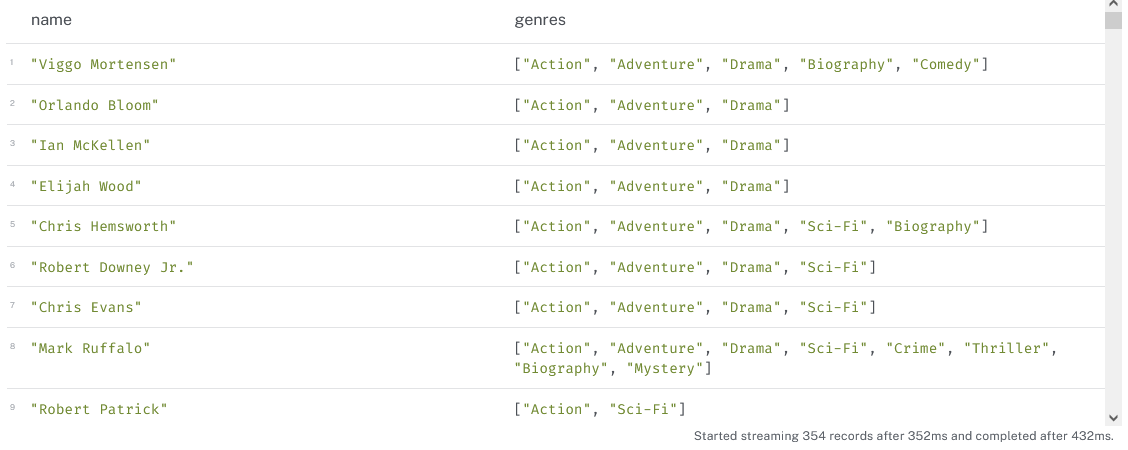

-
query
match (p:Person)-[:ACTED_IN]-(m:Movie)-[:GENRE]-(g:Genre)
return p.name as name,collect(distinct g.genre) as genres
 Graphs & Cypher Introductory Slides
Graphs & Cypher Introductory Slides
Véronique Gendner –
![]() e-tissage.net – Feb 2024
e-tissage.net – Feb 2024